

by: Lana Tkachenko
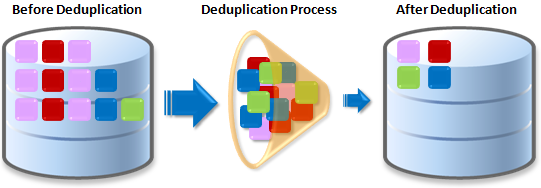
Data deduplication, although not traditionally considered backup software, can be quite handy when backing up large instances of data. The deduplication process works by identifying unique chunks of data, removing redundant data, and making data easier to store. For example, if a marketing director sends out a 10MB PowerPoint document to everyone in a company, and each of those people saves the document to their hard drive, the presentation will take up a collective 5G of storage on the backup disk, tape, server, etc. With data deduplication, however, only one instance of the document is actually saved, reducing the 5G of storage to just 10MB. When the document needs to be accessed the computer pulls the one copy that was initially saved.
Deduplication drastically reduces the amount of storage space needed to back up a server/system because the process is more granular than other compression systems. Instead of looking through entire files to determine if they are the same, deduplication segments data into blocks and looks for repetition. Redundant files are removed from the backup and more data can be stored.
There are three ways for deduplication to occur:
- Inline
- post-process
- source side deduplication
With inline deduplication, data is deduplicated before being stored. This does not require any additional space to store the data prior to deduplication.[1]
Post-process deduplication briefly places all of the backup data on a disk-based staging storage prior to being deduplicated.[2] Then, the data undergoes the deduplication process. Although this method requires more space, it enables faster backups and recovery.
“Source-side deduplication typically uses a client-located deduplication engine that will check for duplicates against a centrally-located deduplication index, typically located on the backup server or media server.”[3]
Despite any of these methods being used, data deduplication is not a stand-alone product and must work in conjunction with other storage solutions.
The question is: Is deduplication worth the extra time and money?
Pros
- Compressing data gives SMBs more bang for their buck, because they can make the space on their current storage devices go further by removing duplicate data.
- “Less data can be backed up faster, resulting in smaller backup windows, smaller (more recent) recovery point objectives (RPOs) and faster recovery time objectives (RTOs).”[4]
- Data deduplication speeds up backup, replication and the disaster recovery processes.[5]
- Deduplication can lead to sizeable savings in terms of time, resources and budget.
- Because deduplication decreases file size, it helps remove the amount of media required to provide a SMB with good quality data recovery.
Cons
- There is a small potential of data loss when data is deduplicated because a deduplication system stores data differently than how it is written. Therefore, the reliability of the data depends on the deduplication system. However, the development of technology over the years has decreased the chance of data loss.
- If using the inline deduplication method, data that does not deduplicate well has the possibility of being erased.
- The source side deduplication method can become easily overloaded with large files, which can slow down backups.
- Data deduplication is not a stand-alone product, it must be used with other backup software.
- Some deduplication methods, such as post process, require more difficult configurations to make them function correctly.
With the abundance of data deduplication tools on the market, most of the cons associated with deduplication can be avoided by choosing the correct software. For SMBs trying to save money on a backup solution, deduplication can significantly decrease the amount of necessary storage space. With deduplication, backup and recovery can be attained much more quickly and without redundancy. Data backup solutions, in conjunction with deduplication, are the perfect way to make sure that data loss is never detrimental to a small business.

Sources
http://searchstorage.techtarget.com/feature/How-data-deduplication-works
http://www.continuitycentral.com/feature0796.html
http://www.computerworld.com.pt/media/2011/02/Data_Deduplication_for_Dummies_Book.pdf
http://en.wikipedia.org/wiki/Data_deduplication