

What is RAID?
RAID (Redundant Array of Independent Disks) was first introduced in 1987 by David A. Patterson, Garth A. Gibson and Randy Katz at the University of California. More importantly, RAID is a well known and widely used form of data protection and disaster recovery.
Terminology:
Mirroring- Mirroring is when data is duplicated and written onto a seperate disk, thus creating an identical disk. This is important because redundancy will help prevent data loss if any disk failure was to occur. However, the versions of RAID that implement this techonology will have lower efficiency due to the duplication.
Striping- Striping refers to the quantity of data that an individual drive can read and write in array at one time.
Parity- This is used for fault tolerance. For example, a parity is when data is calculated from two drives and then stored into a third drive.
Rebuild- This is the process of recovering data when disk failure has occured.
Single or Multiple Bit Corruption- This form of corruption indicate that an error (or more) was made during the writing process.
The Different RAID Levels:
There are nine common forms of RAID, however there are many more that have been developed over the years. The most common forms are:
RAID 0

Pros:
- Since there is no redundant date being stored, this version of RAID has a storage capacity of 100%.
- Great for large data transfers
- No parity generation
- Data can be split across multiple hard drives with a high input/output rate
- This is a more cost effective option since less hardware is needed to store data since nothing is duplicated
- This is a simple version of RAID to implement
- Since information is split up between multiple disks,
- Not an actual level of RAID because it is not fault- tolerant
- Since it does not duplicate data, disk failure can cause a significant amount of data loss (not fault tolerant)
- This is not a good option for critical systems where data is highly important
- Due to its high capacity and speed, this works well for anything that requires a high bandwidth. More specifically, this works well with video or image editing and pre-press applications
RAID 1
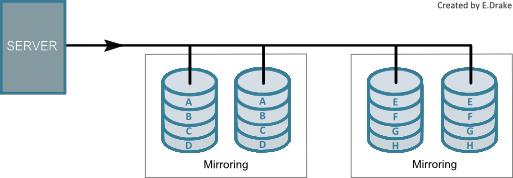
Pros:
- It has a fairly large data storage capacity of 50% (due to mirroring.)
- Works well for large data transfers
- Fast at reading data. It can do one write or two reads per mirrored pair.
- No need for rebuild
- Sometimes it can even sustain multiple simultaneous drive failures
- Simplest RAID storage subsystem design
- Prevents data loss if there is disk failure since all data is mirrored to a second hard disk
- It is fairly easy to implement
- Has the largest disk overhead since it is completely inefficient
- This is not a cost effective solution since one drive is reserved for duplicating data
- The writing speed of RAID 1 is not very efficient since all data is written twice
- There is a high disk overhead
- Since all data is mirrored, this method is good for any application that requires high availability. For instance, companies who need to keep important information while having the ability to access it easily.
- Ideal for accountants and payroll or financial applications
RAID 2
RAID 2 uses Hamming Code which is a linear error correcting code (ECC.) This is when data is recorded onto ECC disks, the code will verify whether the information is accurate and correct it if it is not. So with this form of RAID, information is striped in levels instead of blocks. And with the use of ECC, this level is able to correct single bit errors very well while providing a high data transfer rate at the same time.Pros:
- High transfer rates that increase as the ratio of data disks to ECC disks gets better
- Constant data error correction and detection
- Simple controller design compared to other levels (similar to levels 3, 4, and 5)
- Multiple bit corruption is easily detected
- Possibility of multiple bit corruption and sometimes cannot be corrected
- Can be inefficient when there is a high ratio of ECC disks to data disk with smaller word sizes
- This form of RAID has become almost obsolete because there is no commercial implementations that exist. Especially since the error bit correction logic is extremely complex
RAID 3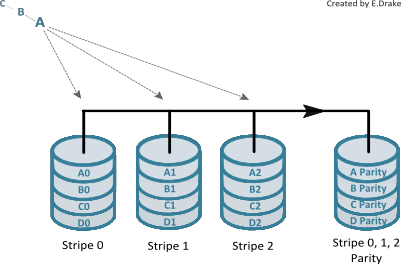
Data is split at byte level, striped then written onto data disks. Stripe parity data is generated on writes and is recorded onto an additional parity disk and is checked on reads. Due to the extreme subdivision of information, multiple hard disks need to be accessed in order to reach one block of information. Because of the characteristics, RAID 3 requires a minimum of three drives.Pros:
- Has high read and write speeds for large file transfers
- Cost effective
- The lower ratio of ECC parity disks to data disks increases efficiency
- Good capacity of hard disks since only one extra disk is needed to store parity information
- Damage caused by disk failure is usually insignificant
- Not a good choice for small data transfers
- Design of the controller is complicated
- Requires a lot of resources and is difficult to do as a “software” RAID
- Application of RAID 3 is limited to certain fields
- In order to access a block of data, more than one hard drive needs to be reached
- Like with RAID 0, this is a better option for any applications that need a high throughput.
- Video production and live streaming
- Image or video editing
- Prepress applications
RAID 4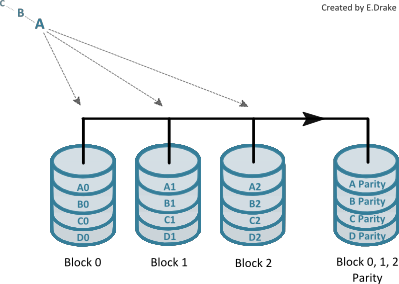
RAID 4 is very similar to RAID 3, since it uses a designated parity disk, however it stripes at block level. It requires a minimum of four hard disk drives. Unfortunately, this level of RAID quickly became obsolete due to its inefficiency.
Pros:
- When allowed, it can perform multiple reads
- Cost effective
- Has a very high data reading rate
- Does not require synchronized spindles unlike RAID 3
- Does not have high performance since only one block of data can be accessed at a time
- Data writing is slow and it has to write for both the data blocks and the parity block
- In order to implement this level, its pre-existing issues must be resolved, thus making it obsolete
RAID 5
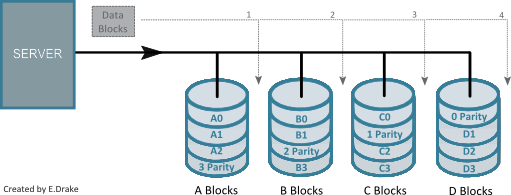
Pros:
- RAID 5 has the highest Read data speed
- Medium write data transaction speed
- Highly efficient since there is a low ratio of ECC parity disks to data disks
- It requires a minimum of three hard drives so it can be cost effective
- Fairly high capacity rate
- If disk failure were to occur, there is the potential of having a medium impact on throughput. Also, it will be difficult to rebuild, especially compared to RAID 1.
- Has one of the more complex controller designs
- The individual block data transfer rate is the same as a single disk transfer rate
-
This level of RAID is more versatile than most. It works well with various forms of servers incuding:
-
Database servers
-
File and application servers
-
Web, e-mail and news servers
-
Intranet servers
-
RAID 6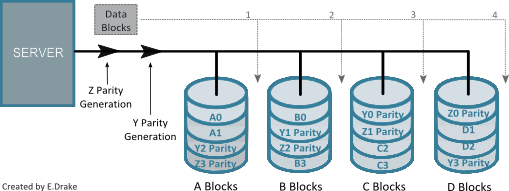
This is an extension of RAID 5 which eliminates the risk of data loss due to disk failure. In this level, there are two independent parity blocks that follow separate algorithms (Hamming Code and Reed-Solomon.) This additional and separate striping allows for a higher possibility of data recovery and prevention of permanent data loss if singular or multiple hard disk drives were to fail. Essentially, this has the highest fault tolerance with the lowest cost.
Pros:
- Has an extremely high and multiple fault tolerance by implementing the second parity write
- Has a high performance for Read operations
- Has a moderate capacity and is not very costly to run. However, it has a slightly lower capacity than RAID 5 due to the second parity write.
- Works well with large data transfers
- Can sustain multiple drive failures at one time
- Great for mission critical applications
- Has a complex controller design
- Performance is not good for small data transfers
- Write time increases as two parity blocks are created
- This holds the same criteria as RAID 5 by working well with various types of servers and uses including:
- File and application servers
- Database servers
- Web and e-mail servers
- Intranet servers
RAID 10
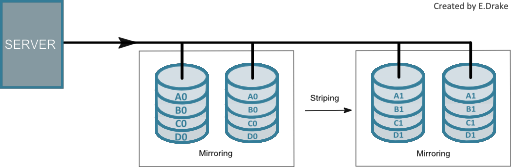
RAID 10 (or RAID 1+0) features elements of both RAID 1 and RAID 0. With this level each block of data is mirrored and stripped. It requires a minimum of four drives however it works very well in the case of multiple disk drive failures.
Pros:
- Has a moderate disk capacity of 50% (this is due to the extra stored copies of data blocks)
- Extremely fault tolerant (same as RAID 1)
- Great for large data transfers
- Depending on the circumstance it can sustain multiple and simultaneous drive failures
- A great solution for those who need RAID 1 but with more protection and performance enhancements
- This is a very costly level of RAID due to the striping and mirroring
- Similar to RAID 3, drive spindles need to be synchronized in order to maintain high performance
- This is an excellent solution for database servers needing both high performance and fault tolerance
RAID 01
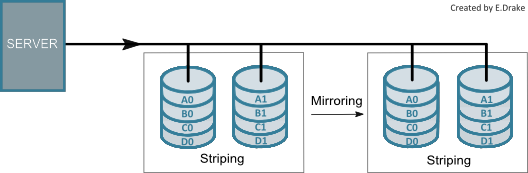
RAID 01 (or RAID 0+1) is very similar to RAID 10, however there is no parity generation. With this level, data is initially striped into a various hard disk drives, then that set is mirrored. Like others, this level requires a minimum of four hard disk drives.
Pros:
- Has a moderate capacity of 50% (due to mirroring)
- Large data transfer rate for larger data transfers
- Has the same fault tolerance as RAID 5
- A great solution for those needing high performance but do not need the maximum reliability
- Unlike RAID 10, this level will essentially become RAID 0 if a single drive failed
- This is an expensive version due to the high and inefficient forms of redundancy
- It takes a while to write
- All drives must be synchronized in order to sustain performance
- This works well for imaging applications or general file servers

More Information on Business Continuity:
Disaster Recovery vs Backup: /IT-Services-Boston/bid/118766/Disaster-Recovery-vs-Backup-Which-is-right-for-you
A business continuity and disaster recovery guide: /disaster-recovery-guide